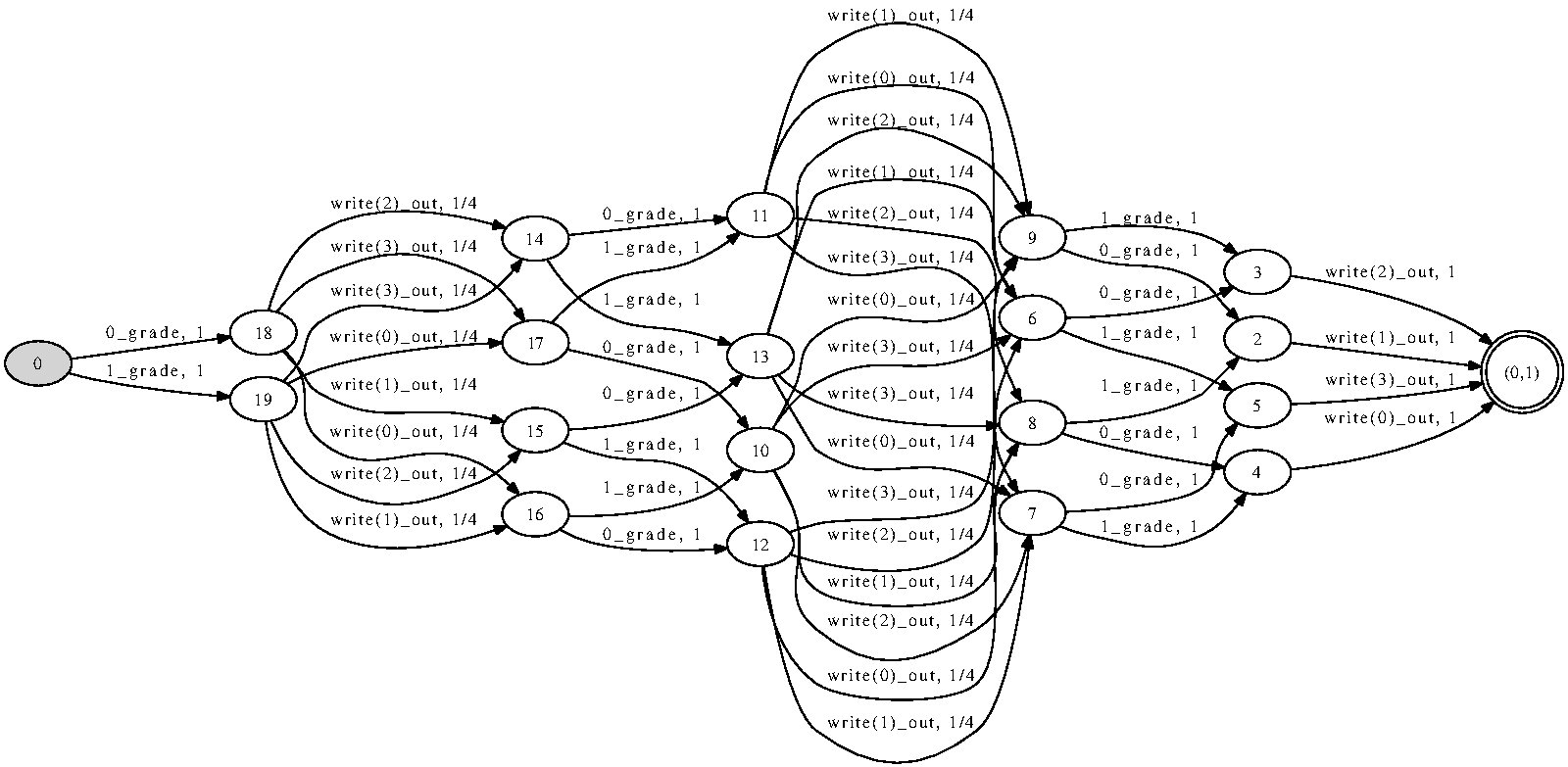
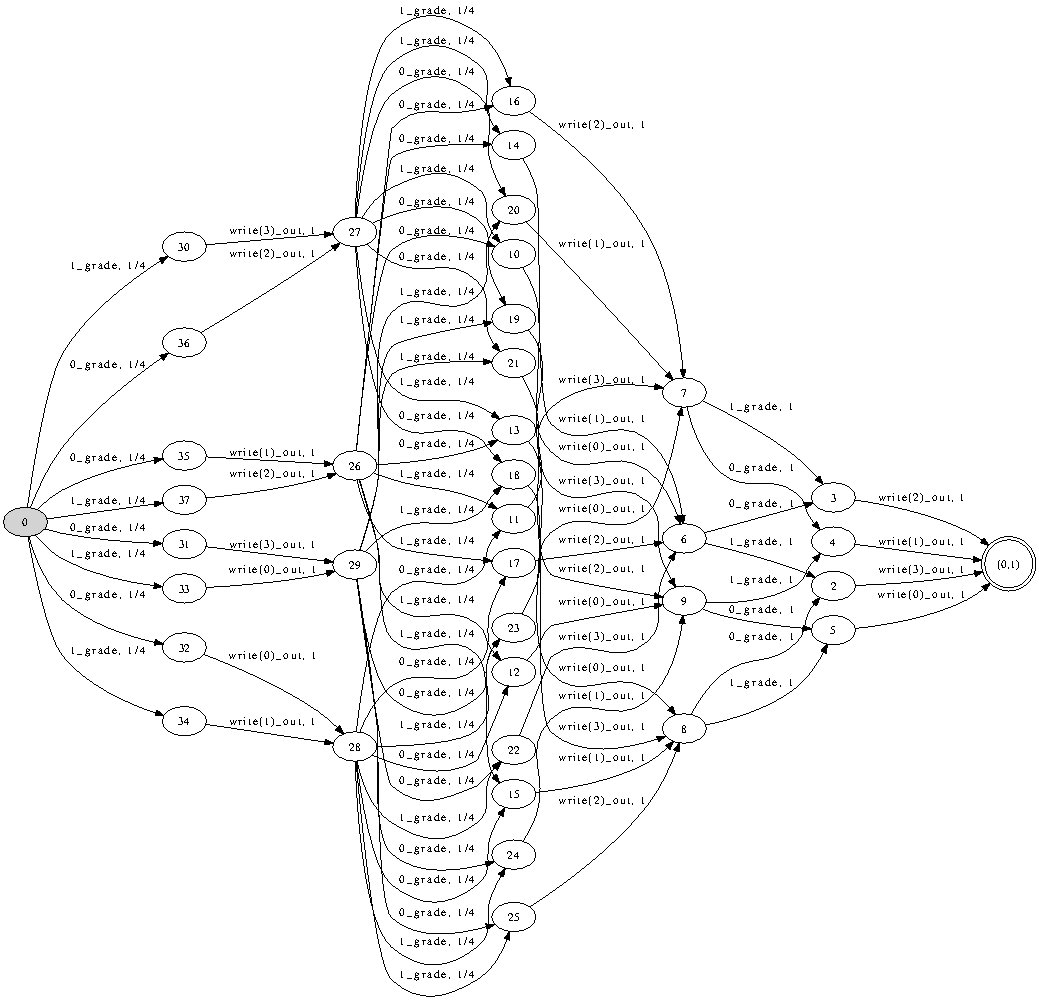
// PRINTS OUT PAIRS (GRADE,ANNOUNCEMENT)
// ANONYMITY CAN BE VERIFIED BY CHECKING
// LANGUAGE EQUIVALENCE WITH SPECIFICATION (grade-spec.txt)
// number of students
//const STUDENTS:= 3;
// grades: 0,1,...,GRADES-1
//const GRADES:=2;
const N := STUDENTS*(GRADES-1)+1;
grade:int%GRADES, out:var%N |-
var%(STUDENTS+1) i;
var%N first;
first:=rand[N];
var%N right;
right:=first;
i:=0;
while(i<STUDENTS) do {
var%N left;
i:=succ(i);
left := if (i=STUDENTS) then first else rand[N];
out := (grade + left) - right;
right := left;
}
:com
// SPECIFICATION TO BE USED WITH grade-impl2.txt
//const STUDENTS:=10;
//const GRADES:=10;
const N := STUDENTS * (GRADES-1) + 1;
grade:int%GRADES, out:var%N |-
var%STUDENTS i;
var%N total;
i:=1;
while(i) do {
total := grade + total;
var%N r;
r := rand[N];
out:=r;
total := total - r;
i:=succ(i)
};
out:= grade + total: com
| G | S | tspec | tprot | sspec | sprot | t←,rand | t←,det | t←,rand | t←,det |
| 2 | 10 | 0.00 | 0.02 | 202 | 1102 | 0.00 | 0.41 | 0.00 | 0.02 |
| 2 | 20 | 0.05 | 0.24 | 802 | 8402 | 0.10 | 26.09 | 0.03 | 0.26 |
| 2 | 50 | 1.75 | 6.46 | 5,002 | 127,502 | 8.08 | 1.21 | 10.07 | |
| 2 | 100 | 25.36 | 82.26 | 20,002 | 1,010,002 | 240.97 | 10.56 | 159.39 | |
| 2 | 200 | 396.55 | 80,002 | ||||||
| 3 | 10 | 0.02 | 0.16 | 383 | 3803 | 0.02 | 5.79 | 0.01 | 0.09 |
| 3 | 20 | 0.22 | 1.64 | 1,563 | 31,203 | 0.69 | 598.78 | 0.23 | 1.33 |
| 3 | 50 | 6.99 | 39.27 | 9,903 | 495,003 | 61.76 | 9.29 | 63.16 | |
| 3 | 100 | 102.42 | 39,803 | ||||||
| 3 | 200 | ||||||||
| 4 | 10 | 0.04 | 0.56 | 564 | 8124 | 0.07 | 37.32 | 0.04 | 0.36 |
| 4 | 20 | 0.53 | 5.47 | 2,324 | 68,444 | 2.25 | 0.77 | 4.95 | |
| 4 | 50 | 15.94 | 142.59 | 14,804 | 1,102,604 | 210.00 | 30.27 | 222.50 | |
| 4 | 100 | 232.07 | 59,604 | ||||||
| 4 | 200 | ||||||||
| 5 | 10 | 0.09 | 1.46 | 745 | 14,065 | 0.17 | 164.87 | 0.10 | 0.68 |
| 5 | 20 | 0.96 | 16.39 | 3,085 | 120,125 | 5.36 | 1.92 | 14.49 | |
| 5 | 50 | 28.81 | 417.58 | 19,705 | 1,950,305 | 508.86 | 62.64 | 335.01 | |
| 5 | 100 | 100 | 417.59 | 79,405 | |||||
| 5 | 200 |